
On Mon, 1 Jan 2001 17:09:50 -0500 Jody Goldberg <jgoldberg home com> wrote:
On Sun, Dec 31, 2000 at 07:06:21AM +0900, Yukihiro Nakai wrote:g_unichar_to_utf8() function in print-cell.c is broken in multibyte environment because it doesn't any multibyte handling.I wrote a new g_unichar_to_utf8() func that can handle multibytes correctly in multibyte environments with gint32. In EUC-JP, 2 byte is normal but some other codeset uses 4 bytes.The comment in src/print-cell.c says 'This is cut & pasted from glib 1.3' If your replacement is better it should go into glib-1.3 and gnumeric. I'll wait for someone more experienced in these details to make this decision.
http://cvs.gnome.org/bonsai/cvsblame.cgi?file=glib/gutf8.c&rev=&root=/cvs/gnome The g_unichar_to_utf8() function in glib 1.3 seems to convert from ISO10646 char to UTF-8 char (First arg is gunichar, == guint32). But g_unichar_to_utf8() in gnumeric is used to convert locale-dependent chars to UTF-8 char. So it will cause no error in glib, but do in gnumeric.
I used #ifdef linux macro because in *BSDs don't haveI'd prefer to see #ifdef HAVE_LANGINFO_H than #ifdef linuxIn this example, I use 'ABC' in EUC-JP multibyte and 'ABC' in ASCII. Below it the char codes for your sake: | ASCII(UTF-8) EUC-JP UTF-8(multibyte) ---+---------------------------------------------- A | 0x41 0xa3 0xc1 0xef 0xbc 0xa1 B | 0x42 0xa3 0xc1 0xef 0xbc 0xa2 C | 0x43 0xa3 0xc1 0xef 0xbc 0xa3This confuses me. 1) It seems as if A == B == C in the EUC-JP case. 2) where can I find some documentation on UTF-8 vs UTF-8(multibyte) ?
Oops. It's a mistake.
1)
| ASCII(UTF-8) EUC-JP UTF-8(multibyte)
---+----------------------------------------------
A | 0x41 0xa3 0xc1 0xef 0xbc 0xa1
B | 0x42 0xa3 0xc2 0xef 0xbc 0xa2
C | 0x43 0xa3 0xc3 0xef 0xbc 0xa3
2)
ASCII UTF-8
Single byte A : 0x41 <-> 0x41
EUC-JP 'A' : 0xa3 0xc1 <-> 0xef 0xbc 0xa1
The EUC-JP 'A' is the double with char 'A', as same as
Japanese character.See the sample mbstr.png, first 'ABC'
is in ASCII, and last 'ABC' is in EUC-JP.
The ASCII 'A' share same char code in both ASCII and UTF-8.
But EUC-JP 'A' is 2 byte in EUC-JP and 3 bytes in UTF-8.
You can make sure with the iconv command of what code in
EUC-JP will be converted in what in UTF-8.
---
Yukihiro Nakai, Red Hat Japan, Development
Attachment:
mbstr.png
Description: PNG image
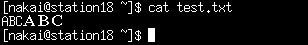{kind=link}