
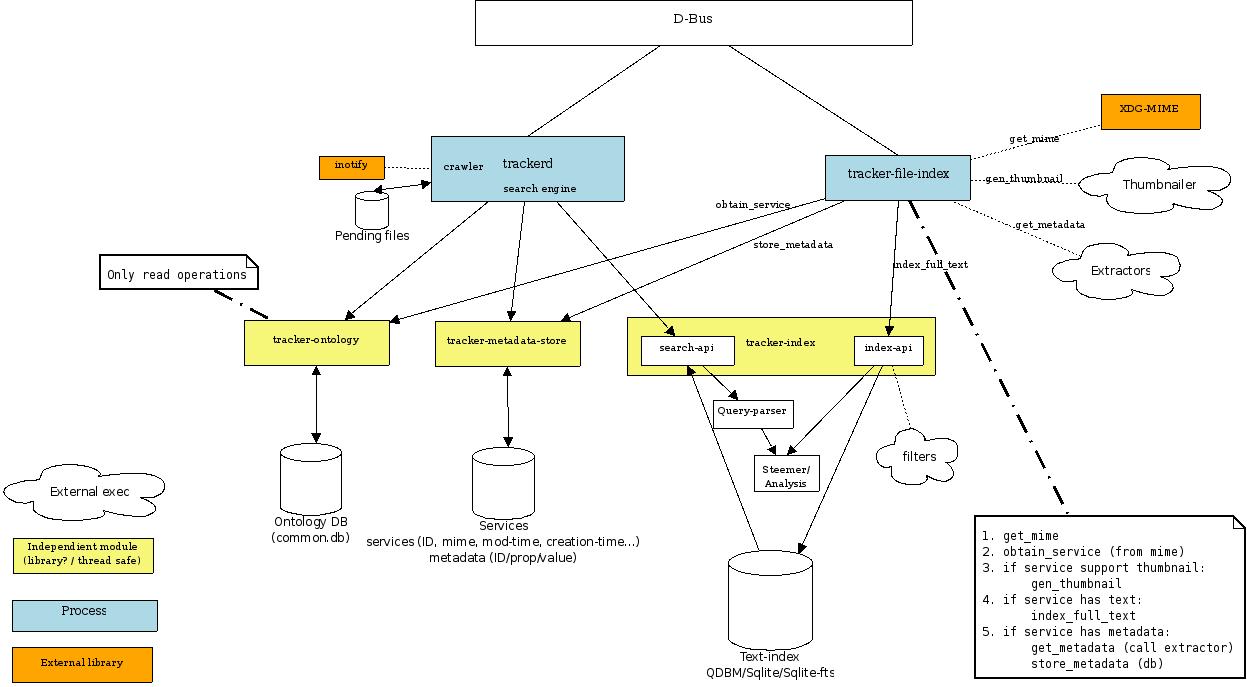
thanks thats very nice Its very close to what I had in mind A few changes/omissions: 1) instead of tracker-index shared lib, only the parser would be shared (because trackerd would need to parse and stem search terms). the search api would not need to be shared nor would any other indexing stuff. 2) trackerd's access to db/index would primarily be read only with exception of ontology updates. for safe NFS use we must avoid separate processes writing to same db at same time. so for storing metadata we would need to pause (via dbus) tracker-file-indexer if its indexing and writing to metadata db (for performance reasons we could include option not to do this and rely on file locking) 3) A User DB which is used for storing user defined metadata + services (tags + any services stored directly in tracker as their primary store like bookmarks and other stuff which is not stored elsewhere on disk) 4) ontology would be part of the metadata store. Both processes would need access to this and virtually no metadata operation could be completed without onto so does not make sense to separate them. As in (3) above metadata store would encompass the user metadata db as well as the indexed metadata db 5) Shared config libs - not just for tracker but for tracker-preferences/tracker-applet as well to sum up on shared libs i think the following is needed: * libtracker-metadata (read/write/search metadata) * libtracker-parser * libtracker-config * libtracker-common (shared utility functions) For the indexer if we have several processes (file-indexer/email-indexer/application-indexer etc) then a lot of index stuff would need to be shared. Im still not certain if to go this way or just have one index process as emails will have file attachments so its not clear cut at the moment anyway forwarding to tracker-list for comment jamie -------- Forwarded Message -------- From: Ivan Frade <ivan frade nokia com> To: jamie mccrack gmail com Subject: Plans for 0.7 Date: Mon, 03 Mar 2008 17:44:22 +0200 Hi Jamie, I prepared a small diagram to clarify the intended architecture for tracker 0.7. I think that a diagram like this can be very useful to understand all required refactorings. It represents (what i understood about) your ideas of two different processes, with my own ideas about how to split the code in clean modules. The xesam stuff is not included, but maybe we can use the diagram to clarify how to integrate it. Could you please take a look at the diagram? If you think it is a good enough approximation we can discuss the details on the mailing list. Of course all questions and comments are welcome. Thank you, Ivan P.D. I attach the diagram in JPEG and .dia
Attachment:
tracker-processes-arch.jpeg
Description: JPEG image
Attachment:
tracker-processes-arch.dia
Description: application/dia-diagram
{kind=link}