
Le Tue, May 28, 2002, à 10:54:00PM +0800, Zhang Lin-bo a écrit:
On Tue, 28 May 2002, Cyrille Chepelov wrote: Bonjour,Le Tue, May 28, 2002, 3:49:50PM +0800, Zhang Lin-bo a rit: OK. I'll try your patch, hopefully today, to check whether it breaks or not on a latin0 workload.Thank you.
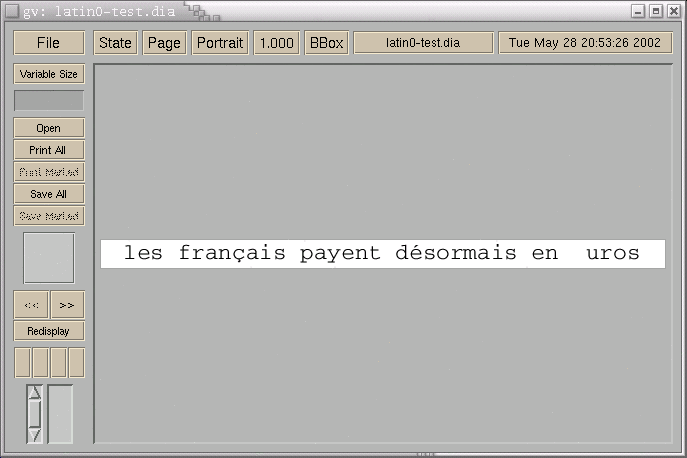
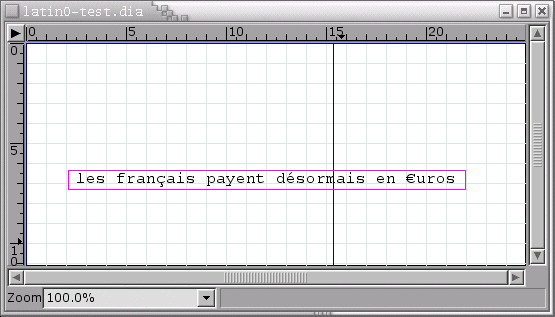
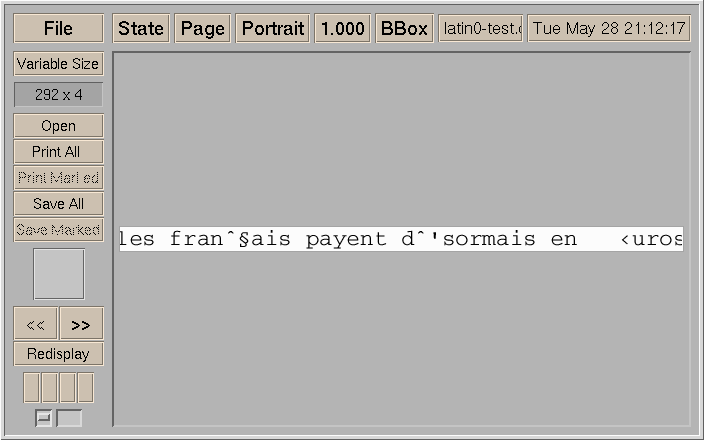
Done. It breaks (see latin0-*). I've made a small dia file with a latin0 text in French (it features both diacritics which were available in latin1, and the euro symbol which triggered the transition from l1 to l0). You can see that GhostScript botches the euro sign; in fact, it's because I have an old font file which has not been updated. Now, if we look at the situation with your patch, we can see it just turns the latin1 diacritics (and latin0, for that matter) into garbage. I think I can bet that if you run the same .eps file on your machine, you will either see the diacritics, spaces or squares, but not the same disaster. This, I believe, is because RH ships a modified version of Ghostscript with UTF-8 capability (which I don't believe is a standard sanctioned by Adobe).
It would be interesting if you could send me a couple sample files (privately). I'm not a Postscript wizard, and while I can read some non-latin alphabets, I'm totally at loss with the CJK writing systems (big surprise)I have attached some sample PS files in ps_samples.tar.bz2, They all contains two same Chinese character (ºº×Ö, or Han Zi, they mean "Chinese characters"). I don't know if the attachment is too large for the mailing list (131KB). If it can't get through, I'll send it to your address.
It went through in public, it seems. Results on my machine (not yet
Chinese-capable in that I haven't run ag*.sh. It does have some Chinese
font packages installed, though):
abiword1.ps: shows "" (two double quote characters) in the upper
left corner.
abiword2.ps: same.
They seem to use some encoding I'm not aware of (but which look on
my latin screen the same as what you typed above). abiword1 includes
some font resource, but the net result is identical.
gnumeric.ps: does show Han Zi (looks the same as the .png you've
sent in the previous tarball) plus the (latin) page number.
They seem to include their own encoding tables, a little bit like we
do, but more aggressive on the total encoding space (we black out a
couple positions). They are using /uni1234 notation.
mozilla.ps: two squares in the upper left corner; lower right corner
shows a square as the separator between 2002, 05 and 28.
(other corners filled with boring ASCII text)
They seem to go through various hoops and jumps to display Unicode
content. They fail, eventually.
I noticed I've got a lot of CJK-related resources and CMaps in my
Ghostscript directory. I'll investigate.
I don't know much. A set of fontnames is defined in the CIDFont directory, and the ag1.sh script can create more font names in the Font directory (both are subdirectories in /usr/share/ghostscripts/Resource), it seems that none of them works with Dia's EPS files.
This looks somewhat familiar to the system described in http://www.aihara.co.jp/~taiji/tops/ (I didn't have the time to understand all the meat there, but I think there are some gems to pick up) Can you download the file "test-ag-h.ps" there, and comment on its viewability on your system ? The solution there looks very appealing to me (OK, I included the postscript in this message)
I don't think so. I have tried with a document containing the single letter 'A' (whose unicode name is /A), and I got the same result as with Chinese characters.
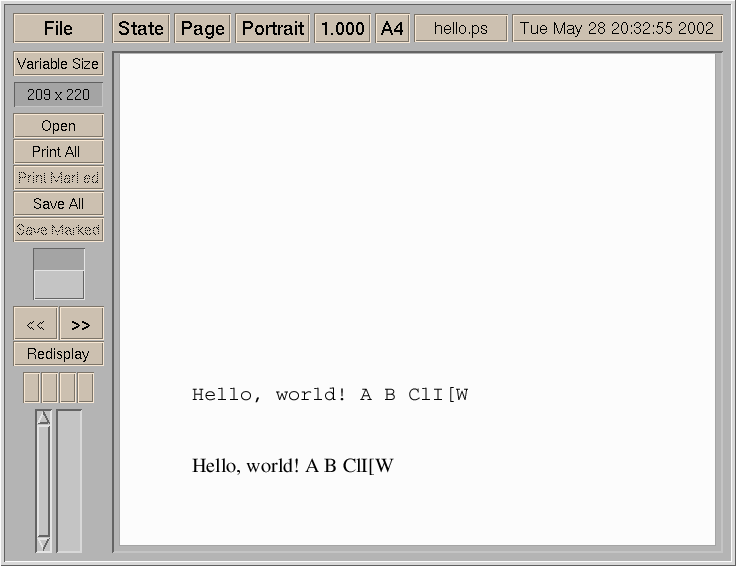
it seems the <1234 5678> notation would work. Can you try the zh_CN-hack1.eps, zh_CN-hack2.eps, and hello.ps, and tell me what do you see on your machine ? (a screenshot of hello.ps would be wonderful).
zh_CN-custom-encoding # what you call nonworking zh_CN-UTF8 # what you call workingmaybe also "zh_CN-GB-EUC", "zh_CN-Adobe-GB1", etc. I know nothing about these encodings, but they must represent some 'standard'.
Indeed they must do. [snip on FreeType -- I'm not much of an expert here. Lars, Robert ?]
Finally, a suggestion: I think dia should save the locale information with a diagram since interpretation of characters is locale dependent (I have a diagram which contains some Chinese characters, when I try to open it in a non zh_CN locale, I get a lot of warnings, such as "** WARNING **: unicode_iconv(u2l, utf=å? ...) failed, because 'Invalid or incomplete multibyte or wide character'...", and the diagram is incorrectly displayed).
This is unneccessary. We'll switch to Pango shortly. .dia files are UTF-8
XML.
-- Cyrille
--
Grumpf.
Attachment:
test-ag-h.ps
Description: PostScript document
Attachment:
hello.ps
Description: PostScript document
Attachment:
hello.png
Description: PNG image
Attachment:
latin0-test.dia
Description: Binary data
Attachment:
latin0-test.eps
Description: PostScript document
Attachment:
latin0-test-gv.png
Description: PNG image
Attachment:
latin0-test.png
Description: PNG image
Attachment:
latin0-test-zlb-patch.eps
Description: PostScript document
Attachment:
latin0-test-zlb-patch-gv.png
Description: PNG image
Attachment:
zh_CN-hack1.eps
Description: PostScript document
Attachment:
zh_CN-hack2.eps
Description: PostScript document
{kind=link}
{kind=link}
{kind=link}
{kind=link}